
Cybersecurity is an ever expanding field where more domains keep getting added as we progress with technology. These domains try to address very specific problems that may arise, for example Container Security or Application Security seek to address issues with Containers and Applications (Web/Android/iOS etc.) respectively. It is however important to remember that all of this ties into Network Security as it is still the primary attack vector and communications method for attackers. Thus to battle the constant updates in attack methodologies using network data, we have attempted to address Domain Generation Algorithms (DGA), a concerning methodology used by attackers to evade detection.
An average SOC analyst cannot be expected to parse through every DNS or firewall log to understand the domain and choose whether or not to flag the same. Whitelisting (or allowing) selected domains to not get flagged would only be a very short term solution, as the list would have to first be created on the basis of expected behaviour and then the historical data, once that is complete it would have to be expanded repeatedly over time. Otherwise, with each new domain that wasn’t in the list would generate an alert and require an investigation. While this can be a generally useful method for companies or organizations which do not expect users to visit sites apart from the few listed, it still would not address the broader concern we have with DGAs and their randomised but quickly changing domains.
We have spoken plenty about the threat and use of DGA or Domain Generation Algorithms, but what are these specifically? As the name suggests these are algorithms which are commonly used by attackers to create a large number of domains, usually for C2 (Command & Control) communications. What makes them difficult to detect or stop is that these are quickly changing, i.e. a DGA domain is used for a very short period of time and then the next one is generated and used. Unless the algorithm itself is cracked, it is not possible to know what the next 5 domains will be. However, this also creates an opportunity for us to detect, that is, since the domains need to be generated randomly, they have a very high entropy. This is due to the fact that to ensure that these domains are unique and not already registered by someone else; algorithms need to keep changing the domains being used with different iterations of the malware. Thus keeping the domains a random set of characters and numbers has the highest rate of success.
So we move onto the next step which is battling the DGAs at what they’re good at; predicting the unpredictable; since they give us a mathematically quantifiable concept “entropy” we will now use this to detect DGA domains. Entropy can be called a measure of randomness, one that we have been trying to quantify across centuries.
Thus, we use a pre-existing formula to measure entropy of the domain, this formula is named “Shannon Entropy”. For those familiar with this particular formula will be aware that it is widely employed while being simple enough to implement without generating a load on the SIEM system which will quite possibly be having to deal with an influx of logs for both DNS and firewall devices, and even more so when C2 communication is active.
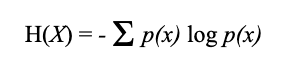
Figure 1.1: Formula for Shannon Entropy
p(x) here stands for the probability of a particular character occurring in the length of the domain. While calculating log(p(x)) we use log base 2 for our calculations.
So how does this help us?
- First we take logs for 5 minutes, we stream this workbook in order to do this every 5 minutes.
- Next we group each log on the basis of the domain it is sending data to or receiving from.
- Then we use the above formula to assign an entropy value to each of the domains on the basis of the use of characters and probability of the characters occurring in the domain.
Now we arrive at an entropy value for all domains that were input for the sake of this calculation. We expect this to be a mix of both C2/malicious and non-malicious domains. Upon measuring the values of entropy for the C2 vs non-C2 domains we notice a pattern of higher entropy being observed for those domains which are generated through DGAs or used previously in C2 communications. For the sake of testing we include C2 domains from previously exposed attacks to further refine our testing methodology.
Now as we do not train any model over here, there is no memory which would affect what the entropy value of a domain would be to make it different across different times, thus the value for any single domain will always be the same, given no change in the formula. This means we can now reliably set a threshold value as per our observation, where if the entropy is above the threshold value that particular domain will be flagged for suspicious activity.
Now this tactic is quite successful, however it requires a very fine tuning and it is often possible to increase the count of false positives if we tune the threshold to be too low. The simple solution is to set a threshold value which is less sensitive and generates a very limited amount of false positives while still giving us flags for malicious domains.
Thus we have successfully found a way to address or solve the problem created by the usage of DGA domains by using Shannon Entropy to calculate the randomness which is inherent in such domains, and weaponising the same to form detection. Of course, the battle doesn’t end here however, for the attackers will be sure to attempt to circumvent this issue. The usage of entropy has become a known technique since DGAs have become common, thus attackers have also taken advantage of the data or information available publicly and they have fine tuned their algorithms to generate longer domains and use limited characters while repeating the same multiple times. This affects the Shannon entropy calculation enough to again possibly evade our detection, however, this comes at a cost of length of the domain. Thus a very simple suggestion or workaround for the same is to set a domain length threshold value in a separate detection, which if exceeded would raise an alert for investigation. Thus covering our bases from 2 ends.
The suggestions provided in this article are a single minded approach to solving a very specific problem in the world of Network Security. While attackers keep developing newer attack methodologies and techniques, it is necessary to ensure that we are still secure against the older, better known attacks and do not lose sight of the same in the chase to catch up or out-do attackers. Security for the Blue Team has to be more focused on being well rounded rather than being first.